Fetch est une API propre aux navigateurs qui permet de présenter des requêtes à un serveur HTTP par voie de programmation, autrement dit depuis du code JavaScript.
Fetch remplace XMLHttpRequest, dont elle est une version plus moderne. En particulier :
- XMLHttpRequest est bien une API asynchrone, mais elle repose sur le recours à des callbacks. Or ECMAScript 2015 a introduit les promesses pour faciliter la programmation asynchrone en échappant au "callback hell", mais XMLHttpRequest n'en tient pas compte.
- Du fait de Same-Origin Policy (SOP), XMLHttpRequest ne permet pas de récupérer une ressource dont l'origine est différente de celle de la page. Or SOP a été tempérée en introduisant Cross-Origin Resource Sharing (CORS), mais XMLHttpRequest n'en tient pas compte.
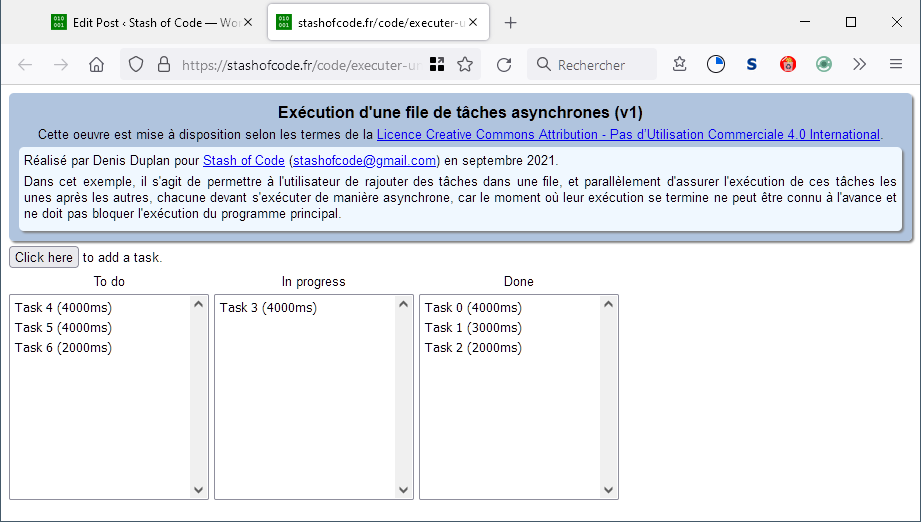
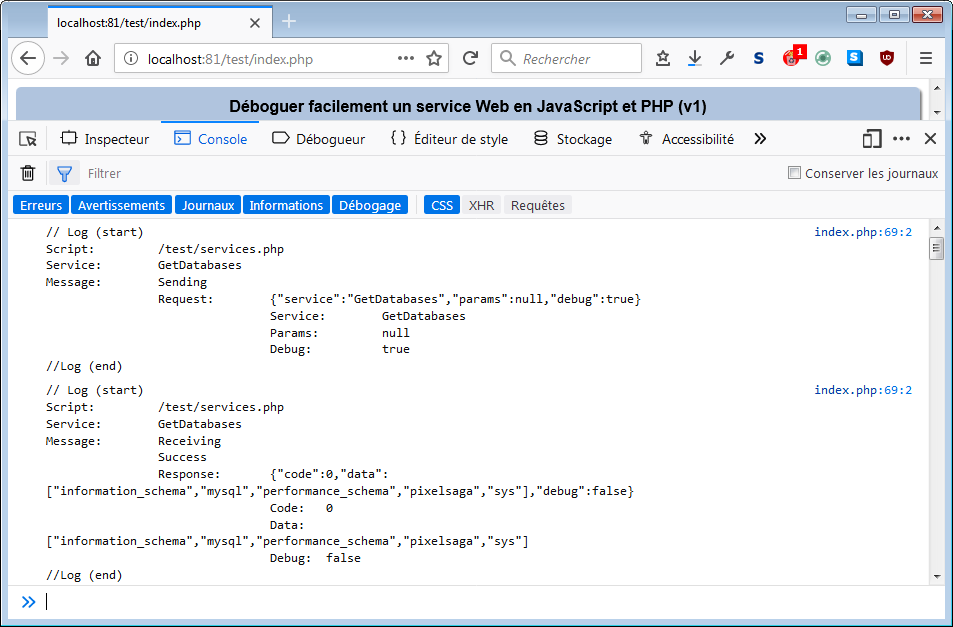
Pour se familiariser avec Fetch, l'on se propose d'écrire une API qui permet de récupérer une série de ressources tout en étant tenu informé de la progression du téléchargement de chacune.

Le code JavaScript devra être aussi simple que possible, mais on n'échappera pas à la mobilisation de quelques concepts fondamentaux : les promesses, la récursivité, les closures, etc. Pas d'affolement, tout est expliqué en détail !
Continuer la lecture de "Téléchargement progressif avec fetch ()"