Depuis l'introduction des promesses puis du sugar coating qui permet d'en faciliter l'usage, tout développeur JavaScript se doit de maîtriser l'art de la programmation asynchrone. Ce sera tout particulièrement le cas s'il souhaite s'investir dans Node.js, où toute fonction devrait en théorie pouvoir être exécutée de manière asynchrone.
Cela implique de repenser la manière de programmer les choses les plus simples. Par exemple, purger à l'infini une file (FIFO) de tâches asynchrones. Dans le monde asynchrone, il est inconcevable d'écrire une boucle où serait logé le programme principal, au seul prétexte de pouvoir régulièrement consulter l'état de la file et exécuter une tâche, s'il en reste, quand l'exécution de la précédente, s'il y en avait, s'est achevée. En un mot, il est hors de question de faire du polling.
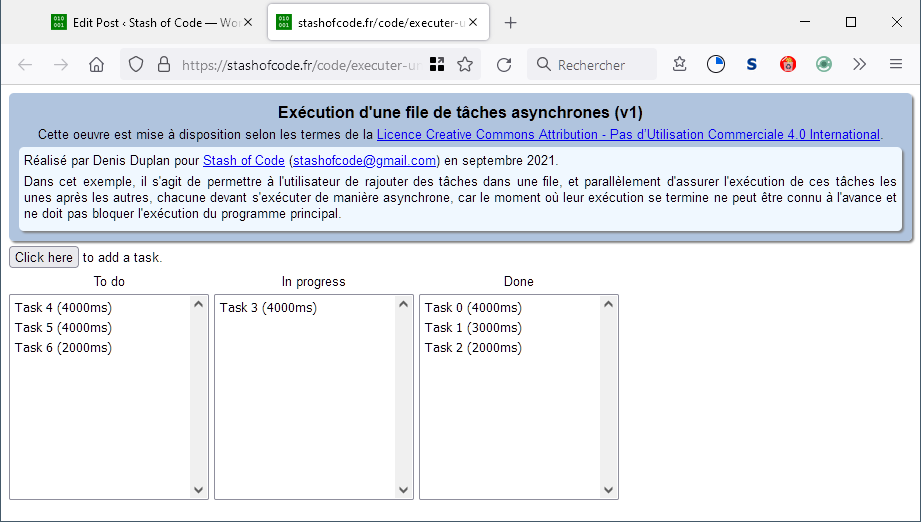
Comment faire ? C'est très simple, et cela constitue un excellent exemple pour s'initier à la programmation asynchrone en JavaScript. Explications dans ce qui suit.
Avertissements
Pour comprendre ce qui suit, il est impératif de savoir en quoi consiste l'asynchronisme en JavaScript, et à quoi sert une promesse dans ce contexte. Pour cela, le lecteur pourra se référer à cet article.
Aussi, quand bien même le code qui va être présenté fonctionne dans le contexte d'une page Web, le lecteur intéressé par Node.js aura tout intérêt à lire cet article qui en présente les bases du fonctionnement, et donc le rôle central qu'y tient l'asynchronisme.
Enfin, une précision. Comme le premier des deux articles évoqués le souligne à la fin, les instructions
async et await ont été introduites dans JavaScript pour faciliter la programmation asynchrone. Ce sugar coating présente l'intérêt de masquer l'existence des promesses, mais pour la bonne compréhension de ce qui se passe, ce n'est pas ce qui sera recherché ici. Il n'en sera donc pas fait usage.
Une interface de test
Le problème est donc le suivant. A tout instant, l'utilisateur doit pouvoir ajouter une tâche à une file, file qu'il faut purger en permanence en exécutant donc les tâches les unes après les autres, dans l'ordre dans lequel elles ont été ajoutées. Autrement dit, aussitôt qu'une tâche est ajoutée à la file, son exécution doit démarrer si aucune tâche n'est en cours d'exécution, ou démarrer automatiquement aussitôt que l'exécution de la tâche précédente sera terminée.
Cliquez ici pour accéder à une page de test minimaliste. Vous pourrez visualiser le code et le récupérer pour travailler avec.
La page permet à l'utilisateur de cliquer sur un bouton pour ajouter une tâche qui apparaît alors dans la colonne de gauche. Lorsque l'exécution de la première tâche de cette liste débute - et dès qu'une tâche arrive en tête de file, son exécution doit débuter -, cette tâche est transférée dans la colonne du milieu. Lorsque cette exécution est terminée - en l'occurence à l'expiration d'un délai aléatoire associé à la tâche lors de sa création -, la tâche est transférée dans la colonne de droite. L'utilisateur peut cliquer à n'importe quel moment sur le bouton sans que cela perturbe la purge à l'infini de la file des tâches : ce "parallélisme" entre le programme principal et la gestion de la file constitue justement l'effet recherché.
Cliquer sur le bouton entraîne ainsi l'exécution de cette fonction
addTask () :
function addTask () {
var delay, option;
delay = randomInt (1, 4) * 1000;
option = document.createElement ("option");
option.innerHTML = `Task ${nonce} (${delay}ms)`;
document.getElementById ("tagToDo").add (option);
fifo.add (nonce, delay, option).then ((task) => {
document.getElementById ("tagDone").add (task.option);
});
nonce ++;
};
Cette fonction appelle la méthode
.add () d'un objet FIFO, en lui transmettant le délai aléatoire au bout duquel l'exécution de la nouvelle tâche doit se terminer, et l'élément HTML OPTION ajouté à la liste de gauche pour figurer la tâche dans la file, élément qui doit être transféré dans la liste de droite quand cette exécution est terminée. La méthode retourne une promesse qui, lorsqu'elle est résolue, effectue ce transfert.
La file des tâches
En effet, il y a une subtilité : l'exécution d'une tâche doit être asynchrone. Autrement dit, l'exécution du programme principal doit pouvoir se poursuivre sans attendre la fin de celle de la tâche de la file en cours d'exécution. Pour illustrer ce point, l'exécution d'un tâche consiste à appeler
windows.setTimeout () pour programmer l'exécution d'une fonction à l'expiration du délai fourni lors de la création de la tâche. L'exécution de cette fonction signale la fin de l'exécution de la tâche.
La file est représentée par un objet
FIFO. Pour ce qui concerne les propriétés, ce dernier contient simplement un tableau des tâches .tasks[] et une référence .task sur la tâche en cours d'exécution :
function FIFO () {
this.tasks = new Array ();
this.task = null;
}
Or, l'on a dit que la file des tâches doit être purgée en permanence, ce qui signifie que si la file contient une tâche ou plus, la plus ancienne de ces tâches doit systématiquement être en cours d'exécution. Par conséquent,
.task doit toujours correspondre à .tasks[0]. Dans ces conditions, pourquoi s'encombrer de .task ? Pour trois raisons :
-
Tout d'abord, il faut bien pouvoir amorcer la pompe. Autrement dit, il faut disposer d'un moyen pour identifier cette situation ou quand bien même il n'y a qu'une tâche dans le tableau, cette dernière n'est pas encore en cours d'exécution. Tester
.task, initialisé ànullà la création de l'objetFIFO, permet cela :.taskdésigne la tâche en cours d'exécution s'il en est, alors que.tasks[0]désigne la tâche en attente d'exécution ou en exécution. -
Aussi, comme expliqué plus loin, la boucle infinie qui permet de purger la file est simulée au moyen d'appels à une méthode de l'objet
FIFOqui amorce la pompe ou passe à la tâche suivante selon qu'aucune tâche n'est en cours d'exécution ou que l'exécution de la tâche courante vient de se terminer. Cette méthode est notamment appelée chaque fois qu'une tâche est ajoutée, ce qui peut survenir plusieurs fois durant l'exécution d'une même tâche, qu'il ne faut donc pas relancer. Tester.taskpermet de savoir que.tasks[0]est en cours d'exécution et ne pas commettre cette erreur, sachant que lorque l'exécution de.tasks[0]se termine,.taskest repassée ànull. -
Enfin, il faut ménager l'avenir. Disposer de
.taskpermet de référencer la tâche en cours d'exécution sans avoir à retirer la tâche de.tasks[]. Cela peut être fort utile si l'on envisage un système plus complexe où l'exécution de la tâche ayant échoué, il faudrait pouvoir la retenter sans avoir à ajouter cette tâche à la fin de la file. Le principe sera donc qu'une tâche n'est retirée de.tasks[]qu'une fois que son exécution s'est bien terminée.
Pour ce qui concerne les méthodes, l'objet
FIFO en comporte deux. La première, .add (). Toutefois, pour comprendre comment .add () fonctionne, il faut déjà comprendre comment fonctionne l'autre méthode, .execute () :
FIFO.prototype.execute = function () {
if (this.task)
return;
if (!this.tasks.length)
return;
this.task = this.tasks[0];
document.getElementById ("tagInProgress").add (this.task.option);
this.task.execute ();
};
Cette méthode est appelée dans deux circonstances :
-
Chaque fois qu'une tâche est ajoutée à la file, c'est-à-dire par
.add (). Cela pemet de démarrer l'exécution de la tâche qui vient d'être ajoutée si jamais la file était vide, circonstance dans laquelle la fin de l'exécution d'une tâche ne peut ainsi amorcer la pompe, puisqu'aucune tâche n'est donc en exécution. - Chaque fois qu'une tâche se termine.
Ce mécanisme qui permet de simuler une boucle infinie. Encore faut-il, pour le complétement décrire, expliquer comment une tâche peut agir sur l'état de la file lorsque son exécution se termine, et plus généralement comment fonctionne une tâche.
Une tâche
Comme dit plus tôt, l'objet
FIFO dispose d'une méthode .add () pour ajouter une tâche :
FIFO.prototype.add = function (id, delay, option) {
var promise;
promise = new Promise ((resolve, reject) => {
this.tasks.push (new Task (
id,
delay,
option,
resolve,
reject
));
this.execute ();
});
return (promise);
};
Cette méthode retourne une promesse qui devra être résolue - on ne gère pas l'échec dans cet exemple - quand l'exécution de la tâche se terminera. Ceux qui ne sont pas familiers avec la technique de la closure, décrite dans cet article, et aussi avec les fonctions fléchées, dont les bases sont rappelées dans cet article, seront déroutés par la syntaxe. Explications :
-
(resolve, reject) => {}déclare une fonction fléchée. Contrairement à un objetFunction, une fonction fléchée ne dispose pas dethis, si bien que toute référence àthisdans son corps fait implicitement référence àthisaccessible dans le scope de la déclaration de la fonction fléchée, autrement dit authisde l'objetFIFO. C'est une closure surthis, qu'il bien plus facile de créer avec une fonction fléchée qu'avec un objetFunction. En effet, l'écriture équivalente serait la suivante - on passe sur des écritures plus élaborées qui exploitentObject.bind ()ouObject.apply (). Elle implique une IIFE pour créer une closure sur objet o qui référence l'objetFIFO:promise = new Promise (function (o) { return (function (resolve, reject) { o.tasks.push (new Task ( id, delay, option, resolve, reject )); o.execute (); });} (this)); -
De même qu'une closure sur
thisréférençant l'objetFIFOest ainsi créée, des clôtures sur le resolverresolveet le rejecterrejectle sont. Cette fois, le mécanisme est explicite : le constructeur de l'objetTaskreçoit notamment en paramètres les références sur ces fonctions définies dans le scope englobant du constructeur de l'objetPromise.
In fine, en plus du délai au bout duquel la tâche doit se terminer et de la référence sur l'élément HTML qui la représente, le constructeur de l'objet
Task récupère des références sur l'objet FIFO via this, et sur le resolver et le rejecter de l'objet Promise qui correspond à la promesse à résoudre quand l'exécution de la tâche se termine. Ce dernier point est d'importance capitale : il montre comment on peut créer une référence externe à la promesse sur une fonction dont l'appel permet de modifier l'état de la promesse en question.
Dès lors, le code qu'il reste à présenter n'a rien de surprenant. Le constructeur de l'objet
Task n'est qu'une chambre d'enregistrement... :
function Task (id, delay, option, resolve, reject) {
this.id = id;
this.delay = delay;
this.option = option;
this.resolve = resolve;
this.reject = reject;
};
...et sa méthode
.execute () se contente de programmer l'appel au resolver à expiration du délai par un appel à window.setTimeout (), qui rend la main immédiatement, ce qui permet de simuler le comportement d'une tâche asynchrone :
Task.prototype.execute = function () {
window.setTimeout (() => {
this.resolve (this);
fifo.task = null;
fifo.tasks.shift ();
fifo.execute ();
},
this.delay);
};
Au passage, l'on notera ici encore le recours à une fonction fléchée pour créer implicitement une closure sur
this qui référence, dans le corps de la fonction de rappel fournie à windows.setTimeout (), l'objet Task. Pratique pour accéder au resolver !
Cette fonction de rappel, justement, appelle le resolver, puis modifie l'état de la file pour acter l'heureuse fin de l'exécution de la tâche. Cela consiste à sortir la tâche de
FIFO.tasks[] et passer FIFO.task à null, avant d'entreprendre de relancer la boucle infinie en appelant FIFO.execute (), selon le principe expliqué plus tôt. Sans doute, il aurait été plus propre d'appeler une méthode de FIFO pour faire cela, mais dans le cadre de cet exemple, l'idée était d'aller à l'essentiel.
run-to-completion et promesse
Inévitablement, une question taraude le développeur qui se lance dans la programmation asynchrone : quel contrôle exerce-t-il sur le séquencement des opérations ? Programmer des fonctions asynchrones, n'est-ce pas un peu lâcher dans la nature des fonctions qui pourraient être appelées à tout instant, au risque que l'exécution de l'une n'interfère avec celle d'une autre ?
Savoir qu'en JavaScript, l'exécution d'une fonction ne peut pas être perturbée par celle d'une autre qui serait initiée par autre chose qu'un appel explicite à la seconde par la première - une manière simplifiée de présenter le fameux principe du run-to-completion - a quelque chose de rassurant... pour autant que l'on comprenne bien ce que cela signifie quand une promesse est impliquée !
Par exemple, quelle valeur de
flag sera affichée ? :
var flag = false;
function f () {
p = new Promise ((resolve, reject) => {
flag = true;
resolve ();
flag = false;
});
p.then (() => console.log (flag));
}
f ();
C'est
false. En effet, pour être plus clair, dans ce cas général d'utilisation d'une promesse... :
function f (resolve, reject) {
resolve ();
}
function g () {
console.log ("Done");
}
p = new Promise (f);
p.then (g);
...l'exécution de la fonction
g () passée à .then () n'intervient jamais avant la fin de l'exécution de la fonction f () passée au constructeur de la promesse. Tout se passe comme si l'appel à resolve () dans le corps f () ne faisait que rajouter une tâche consistant à exécuter g () dans la boucle des tâches du moteur de JavaScript, que ce dernier traitera donc après celle qui consiste à exécuter f ().
C'est l'une des garanties qu'apportent les promesses, comme Mozilla l'explique ici. C'est assez déroutant à première vue, mais rassurant à seconde vue, car cela implique notamment que le moment où le resolver est appelé dans le corps de la fonction de la promesse importe peu.