Tandis que les scénaristes et les acteurs faisaient grève outre-Atlantique, le feuilleton de l'IA a continué comme jamais, nous assurant une distraction quotidienne à défaut de nouvelles séries de science-fiction.

Comme le lecteur pourra le constater, ces derniers mois ont apporté leur lot d'innovations techniques, mais aussi réglementaires. Plus que jamais, l'informatique devient un univers compliqué, où il est n'est plus seulement nécessaire de maîtriser la technique ; il faut de plus maîtriser les règles qui en contraignent l'emploi : celles relatives à la protection des données personnelles, à la sécurité, aux impacts environnementaux, et donc désormais aussi à l'intelligence artificielle.
NB : Ce billet a été rédigé mi-décembre par un humain et non une boîte de conserve, et publié dans Programmez! #261 de janvier 2024.
Psychodrame à OpenAI

Et soudain, c'est le drame ! Vendredi 17 novembre 2023, une date à marquer d'une pierre blanche : le board d'OpenAI vire son CEO comme un malpropre, sans préciser rien de plus que "he was not consistently candid in his communications with the board". Or qu'on y songe : Sam Altman, ce n'est pas moins que le visage de l'IA pour le monde entier, tout particulièrement les régulateurs et les financiers !
Aussitôt, les commentateurs de Hard Fork, le podcast tech et rigolo du New York Times, interrompent leurs vacances de Thanksgiving pour nous faire suivre le soap sur une semaine (ici, puis là, et enfin là). Au final, c'est bientôt comme dans Junta, ce jeu de plateau poilant qui met en scène un coup d'état en Amérique du Sud : après avoir annoncé faire la guerilla (créer sa start-up) puis être passé à l'ennemi (Microsoft l'embauche pour monter un lab), l'ex-generalissimo s'adjoint le soutien des financiers (après avoir investi 13 milliards de dollars, Microsoft ne souhaite pas repartir de zéro) et de la populace (menace d'une majorité de salariés d'OpenAI de démissionner), il redevient generalissimo (Sam Altman, le retour), les factieux sont fusillés dans la cour (le board est dissous), ils sont remplacés par quelques compañeros (un ex-secrétaire au Trésor et un ex-CEO de Salesforce, ça rassure), en attendant que d'autres les rejoignent (Microsoft devrait y gagner déjà un siège d'observateur). "I have never been more excited about the future", explique Sam Altman dans un mémo signalé par The Verge. On le serait à moins...
Quand on tente un coup, mieux vaut ne pas le rater ? Sans doute, mais d'après les commentateurs, il y a beaucoup plus à retenir de ce qui vient se passer.
La structure n'était-elle pas vouée à l'échec ? Comme en témoigne un diagramme d'OpenAI ressorti par Ars Technica, le board tenait les rênes d'une charity dont dépendaient des entités pour leur part totalement business ; caritatif et commercial, un étrange mélange qui tient à l'histoire d'OpenAI.
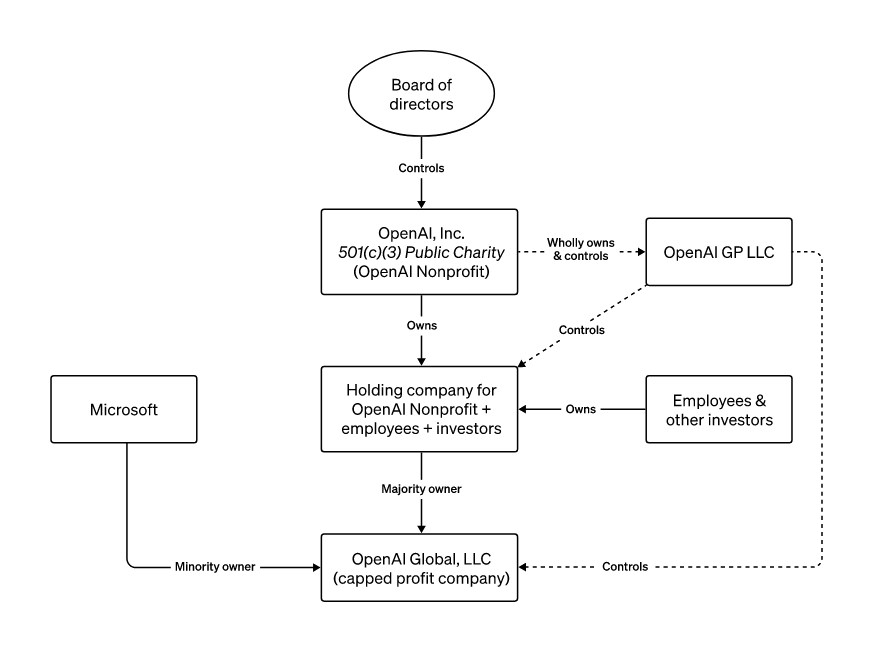
Aussi, comme l'expliquent nos joyeux drilles de Hard Fork dans le dernier de leurs Emergency podcast évoqués, "this war in AI between sort of the capitalists and the catastophists [...] as of now is over: the capitalists have won". La presse économique ne manque pas de tirer un pareil bilan : "With Sam Altman's return, a shift in AI from idealism to pragmatism" titre The Economist, "OpenAI and the rift at the heart of Silicon Valley" titre le Financial Times. Ce dernier va jusqu'à y voir une nouvelle déroute pour l'effective altruism, car deux des maladroits putschistes s'en revendiquaient – tout comme Sam Bankman-Fried en son temps, est-il perfidement rappelé.
Toutefois, avec du recul, c'est sans doute aller bien loin que de voir dans cette histoire le triomphe d'une idéologie sur une autre au terme d'un combat homérique. Comme le suggère la lecture d'un passionnant long read de The New Yorker rédigé à tête reposée, il faut sans doute plus y voir une querelle de personnes, et retenir que Microsoft, qui a tout misé sur OpenAI en y injectant des milliards et en mettant GPT au cœur de ses produits, a eu très chaud, mais s'en tire très bien.
Executive Order et AI Act

Comme il en va avec toute nouvelle technologie, même si elles sont souvent exagérées, les préoccupations quant aux conséquences néfastes de l'IA sont légitimes. D'ailleurs même Sam Altman s'en faisait l'écho à tout bout de champ. Sans doute, son discours était ambigu, en ceci que c'était certainement pour lui un moyen de faire pression pour imposer sa version d'une régulation qu'il savait inéluctable. C'est que dans ce nouveau domaine, il n'a échappé à personne que les gouvernements cherchent à contrebalancer rapidement les ambitions d'une tech qui, par le passé, n'a pas démontré sa capacité à se réfréner d'elle-même.
En fait, ils se font la course. Pourquoi ? Car en matière de régulation, c'est le premier qui tire qui a raison. Aux Etats-Unis notamment, le législateur se souvient de la leçon, quand en refusant de réguler les médias sociaux pour ne pas entraver une industrie naissante, il a laissé libre champ à l'Union Européenne pour produire un Digital Services Act qui, même si a été tardif puisqu'il n'est entré en vigueur que cette année, constitue désormais une référence.
Toutefois, c'est délicat. Mi-octobre, à l'occasion de l'AI Safety Summit organisé par le gouvernement anglais, The Economist résumait bien le problème : "The world wants to regulate AI, but does not quite know how". En fait, l'article souligne que les enjeux sont plus généraux que le seul comment : il faudrait d'abord savoir quoi réguler, et avant même, pourquoi. Sur tous ces points, pas de consensus.
Comme rapporté dans une précédente chronique, des régulations n'en étaient pas moins en gestation depuis des mois. La pression des échéances électorales aidant - élections présidentielle et européennes -, l'urgence s'est finalement trop faite sentir des deux côtés de l'Atlantique. Fin octobre, Joe Biden a court-circuité le Congrès en dégainant un massif Executive on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence ; et début décembre, le trilogue entre le Conseil de l'UE, la Commission européenne et le Parlement européen a débouché sur un accord sur le projet de règlement Artificial Intelligence Act. L'eau coulera sous les ponts avant que ces régulations ne fassent sentir leurs effets, mais la dynamique semble amorcée.
Pour ce qui nous concerne, Euractiv rapporte que la négociation a achoppé sur deux points, à savoir le recours à l'IA pour la RBI (Remote Biometric Identification) et le statut des foundation models. Ces derniers correspondent aux "systèmes d'IA à finalité générale" auxquels le Parlement européen a introduit une référence en juin dernier dans le projet de règlement pour l'actualiser – ce dernier remontant à avril 2021, soit antérieurement à l'apparition de ChatGPT, il se fondait sur la qualification d'un "système d'IA" d'après sa finalité. Euractiv rapporte que la France souhaitait que de tels systèmes soient régulés, jusqu'à ce que la start-up Mistral sorte du chapeau et que le pays renverse alors sa position. L'affaire n'a pas manqué de faire polémique, d'autant plus qu'à cette occasion, un ex-secrétaire d'Etat au numérique a joué les lobbyistes. Edgar Faure se serait régalé : "Ce n'est pas la girouette qui tourne, c'est le vent", n'est-il pas d'autant plus de circonstance de rappeler ?
Enfin bref, pour le développeur, il en ressort que tant aux US qu'en UE, ces modèles feront finalement l'objet d'une régulation particulière. Ils seront identifiés par la puissance de calcul requise pour les entraîner. Ainsi, dans l'executive order, il est notamment question de modèles entraînés via plus de 1026 opérations sur des entiers ou des flottants, tandis que dans l'AI Act, selon Euractiv, il serait question de modèles dont l'entraînement nécessite une puissance de plus de 1025 FLOPS, soit dix fois moins. Le critère retenu est a priori étonnant, mais quel autre choisir, puisque par définition, ces modèles n'ont pas de finalités spécifiques ? Après, c'est peut-être que la catégorie ne fait aucun sens... En tout cas, ce seuil devra pouvoir être repensé si l'on en juge d'après les progrès dont il est question plus loin dans cette chronique.
Qui n'a pas son LLM ?

Début décembre, Google présente Gemini, plus qu'un LLM, une IA multimodale – texte, vidéo, image, voix, etc. –, à l'appui d'une vidéo saisissante Hands-on with Gemini: Interacting with multimodal AI qui montre comment l'IA reconnaît ce qu'une personne lui montre de diverses manières : je te dessine un canard, et l'IA reconnaît un canard ; je te mime un jeu de mains, et l'IA reconnaît pierre-papier-ciseaux ; etc. Problème, comme TechCrunch le pointe dans la foulée, la vidéo est un fake, l'IA ayant répondu à des demandes beaucoup plus travaillées que celles, très intuitives, qui sont données à voir. Après le lancement très raté de Bard, voilà qui ne va pas arranger l'image de Google. "How can anyone trust the company when they claim their model does something now?", interroge justement TechCrunch.
Quelle singulière situation que celle de Google, pourtant largement à l'origine de cette floraison de LLMs que l'on connaît depuis l'apparition de ChatGPT – rappelons que GPT signifie Generative Pre-trained Transformer, et que le transformer est une architecture présentée par des chercheurs de Google en 2017. Le géant apparaît bien en peine pour suivre l'agitation qu'il a suscitée. Ne lui faudrait-il pas chercher la solution ailleurs, comme Microsoft l'a fait avec OpenAI ? Ainsi que le long read de The New Yorker déjà cité le rapporte, dès le départ, la conviction lucide du CTO de la firme de Redmond a été que "Microsoft – which has more than two hundred thousand employees, and vast layers of bureaucracy – was ill-equipped for the nimbleness and drive that A.I. development demanded."
Pendant ce temps, les nouveaux LLMs fusent comme des feux d'artifice sur un champ de foire. Parmi les plus notables, citons, rien que pour ces tous derniers mois :
- GPT-4 Turbo d'OpenAI, une version améliorée du LLM GPT-4, dont il est notamment proclamé que la context window a été quadruplée pour être portée à 128 000 tokens, et qu'il crache du JSON rigoureux ;
- Phi-2 de Microsoft, un LLM de seulement 2,7 milliards de paramètres, dont les performances affichées sont supérieures à celles de modèles qui en comportent jusqu'à 25 fois plus ;
- Mixtral de Mistral, un LLM de 8x7B, soit une cinquantaine de milliards de paramètres, dont il est dit que les performances sont notamment supérieures à celle de Lllama 70B et de GPT 3.5.
Début novembre, l'événement à ne pas louper par les amateurs de LLMs était le DevDay d'OpenAI. Parmi les nombreuses annonces, dont celle de GPT-4 Turbo à l'instant évoqué, il faut tout particulièrement retenir celle de GPTs, une plate-forme permettant à chacun de personnaliser ChatGPT via l'outil GPT Builder avec ses propres données, et de mettre à disposition le tchat résultant sur GPT Store.
Le concept est intéressant puisqu'il semble devoir permettre d'élargir massivement la base des créateurs de tchats. Toutefois, s'il présente l'intérêt de ne pas requérir de connaissances techniques, il présente l'inconvénient d'avoir à loger son tchat dans le giron d'OpenAI. Pour ceux qui souhaitent un petit tchat bien à soi, il est toujours possible de récupérer Phi-2 et Mixtral pour inférer en local, car ces modèles sont pour leur part proposés au téléchargement, notamment sur l'incontournable dépôt Hugging Face.
2024, l'année des lilliputiens ?

Ainsi, à quelques jours de Noël, Microsoft dépose donc au pied du sapin Phi-2, un LLM de seulement 2,7 milliards de paramètres - en fait, il faut dire SML, pour Small Language Model, maintenant. Comme la lecture du post The surprising power of small language models qui l'accompagne le montre, les performances affichées sont étonnantes, puisque Phi-2 fait aussi bien sinon mieux que Llama 2 7B, 13B et même 70B, ainsi que Mistral 7B, tout particulièrement en matière de maths et de code.
AI Explained a consacré d'intéressantes vidéos à Phi sur YouTube (ici et là), notamment pour commenter Textbooks Are All You Need, l'article qui a accompagné la sortie de Phi-1, il y a moins de six mois. Le titre fait évidemment référence au célébrissime Attention Is All You Need où Google a introduit le transformer. C'est assez gonflé de la part des auteurs, mais force est de constater que l'impact de leurs travaux pourrait être tout aussi déterminant pour l'avenir des LLMs.
Le truc des inventeurs de Phi, c'est de prêter beaucoup d'attention à la qualité des données d'apprentissage. En l'espèce, plutôt que d'utiliser tout le fatras qui traîne sur le Net, ce sont des données synthétiques – c'est-à-dire produite par IA – textbook quality qu'ils ont produites à l'aide de GPT à partir d'une base de code gigantesque – plus de 35 millions de fichiers et exemples tirés de The Stack et StackOverflow. En gros : "isole le code le plus pédagogique et utilise-le pour générer des bouquins qui enseignent comment programmer".
Ce n'est finalement que le dernier développement en date d'efforts qui visent à faire tourner un modèle sur de petites configurations, et de là à s'interroger sur la mesure dans laquelle il est possible de réduire un modèle sans trop en dégrader les performances.
Le grand public a pu en découvrir un exemple à l'occasion de la fuite de Llama, dont il a été rappelé dans une précédente chronique comment il avait fait l'objet d'une opération dite de quantization visant à réduire le nombre de bits sur lequel ses poids sont codés pour parvenir à inférer sur une configuration aussi réduite qu'un Raspberry PI. Mais il existe plus généralement bien d'autres techniques d'optimisation, comme LoRA (Low-Rank Adaptation), une technique de PEFT (Parameter-Efficient Fine-Tuning), qui consiste à limiter l'apprentissage lors du fine-tuning à un nombre limité de poids supplémentaires, laissant les poids originaux intacts.
Du coup, présentant Phi-2, AI Explained pose très justement la question : "Small New Models to Change the World?" Qui vivra, verra, mais cela semble bien parti pour être le cas. Avec à la clé une salubre mise en question de la consommation d'énergie qu'engendre le recours aux modèles. Début décembre, une étude pionnière déchiffrée par MIT Technology Review ne met-elle pas en évidence que générer une image avec le moins efficient des modèles consomme autant d'énergie que recharger un téléphone ? C'est en au point que mi-décembre, le Wall Street Journal rapporte que Microsoft cherche à obtenir l'autorisation de bâtir ses propres centrales nucléaires...
De précieuses ressources pour s'informer

Le lecteur fidèle de cette chronique se souvient que dans la précédente, l'auteur avait pointé quelques ressources soigneusement sélectionnées pour se former au DL.
Or dans un domaine aussi dynamique, se former ne suffit pas : il faut se tenir en permanence informé, sous peine de passer du jour au lendemain pour un dinosaure. En conséquence, voici une sélection tout aussi drastique de sources d'informations à surveiller au quotidien :
- Hard Fork, un podcast tech et rigolo qui rend compte des innovations touchant le grand public sans rentrer dans les détails techniques ;
- Import AI, une newsletter plus technique qui rapporte une sélection des innovations de la semaine en l'accompagnant d'un commentaire "Why this matters" toujours intéressant ;
- Last Week in AI, à la fois une newsletter et un podcast eux aussi plus techniques, qui rapportent aussi exhaustivement que possible les innovations de la semaine ;
- AI Explained, une chaîne YouTube qui s'inscrit dans la lignée d'Import AI et Last Week in AI, mais qui donc présente l'intérêt de le faire vidéo à l'appui ;
- TWIML, un podcast lors duquel un acteur de l'industrie de l'IA est interrogé de manière toujours aussi approfondie que pertinente sur ses travaux en cours.