En avril 2023, je décrivai dans un article publié sur ce blog puis dans Programmez! mon aventure avec ChatGPT. Nous en étions alors à la version 3.5 du LLM sous-jacent GPT, la version 4 étant sortie quelques semaines plus tôt, en pleine rédaction de l'article - trop tard pour s'y remettre.
Le constat était décevant, car j'identifiai huit problèmes... :
- lorsqu'il génère du code, ChatGPT risque de s'interrompre sans possibilité de reprise ;
- ChatGPT peut générer des codes différents en réponse à une même demande ;
- ChatGPT peut générer un code qui ne répond pas aux besoins ;
- par défaut, ChatGPT utilise des espaces et non des tabulations pour indenter le code ;
- ChatGPT peut générer un code qui n'est pas efficient ;
- ChatGPT peut générer du code inutile ;
- ChatGPT peut générer du code qui semble répondre aux besoins, mais qui n'y répond pas ;
- ChatGPT peut générer du code qui répond à des besoins qui n'ont pas été formulés.
...mais j'en concluai que "tel le client de Palace que j'évoquais, il ne faut jamais désespérer : quelqu'un, un jour, nous livrera bien une AI qui, en matière de code, génèrera autre chose que de la soupe à la moumoute".
Des millions d'années plus tard à l'échelle temporelle des progrès de l'IA générative, c'est peu dire que ce voeu a été exaucé...

Beaucoup de bruit plus pour rien
Qui code encore à la mano, sans assistance d'un Claude pour l'assister, quand ce n'est pas l'inverse ? A vrai dire, n'est-ce d'ailleurs même pas dépassé, depuis qu'il est question de ce qu'Andrej Karpathy a désigné comme le vibe coding ? Il faut être tragiquement déconnecté des réalités pour ne pas avoir réalisé que dorénavant, tout un chacun peut produire des applications sans rien connaître au code, qui répondent vraiment à de vrais besoins. Enfin, il s'en trouve encore, avant tout chez ceux qui ne sont jamais intéressés à ce que pouvait être code. Pour s'en convaincre, il suffira d'écouter Kevin Roose faisant la leçon Nathalie Kitroeff dans un épisode de The Daily mi-février dernier. Clairement, l'illettrisme agentique prospère sur l'illettrisme informatique, même chez ceux qui ne sont pas les plus vieux ni les moins bien informés de l'état de ce monde.
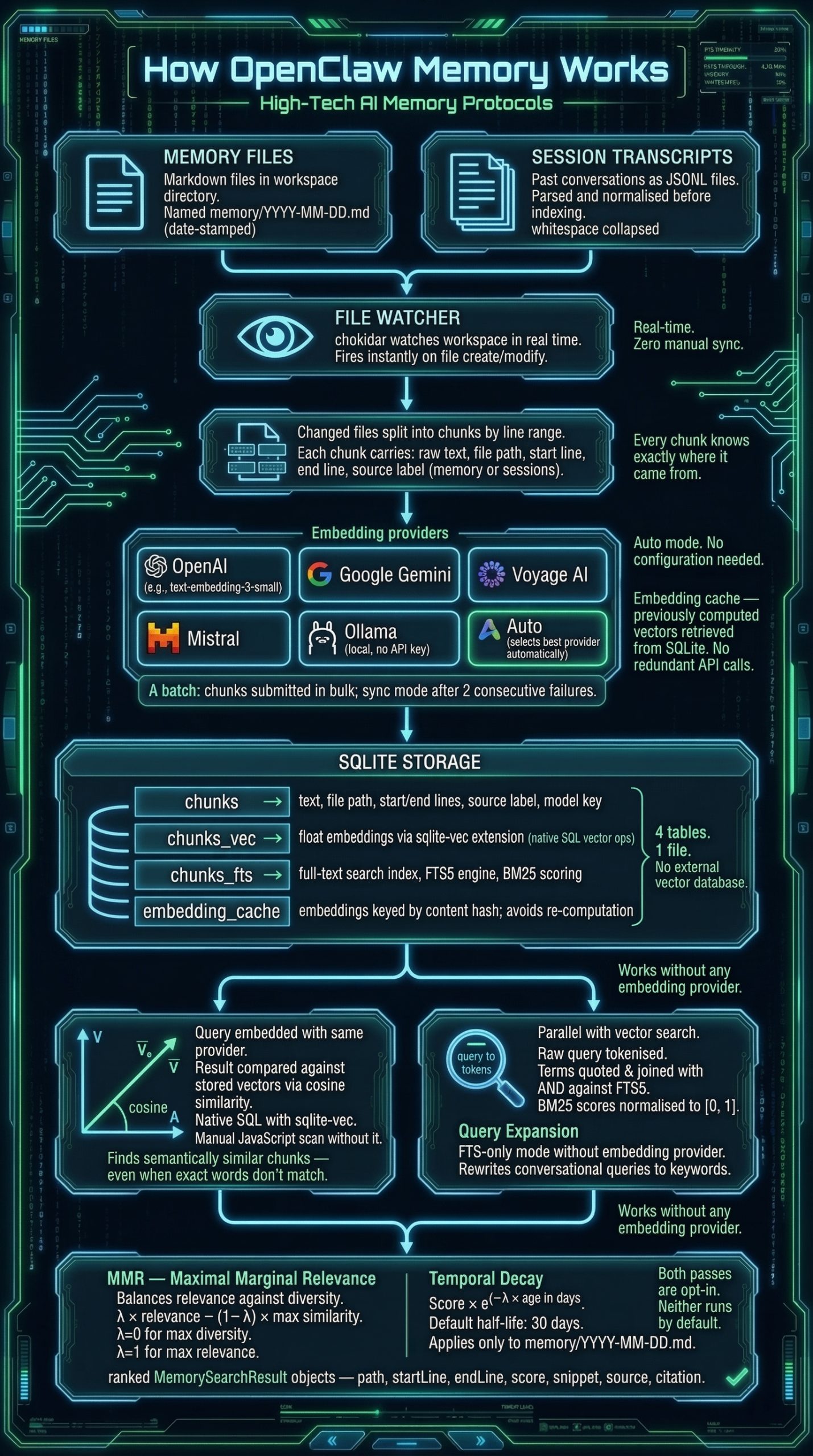
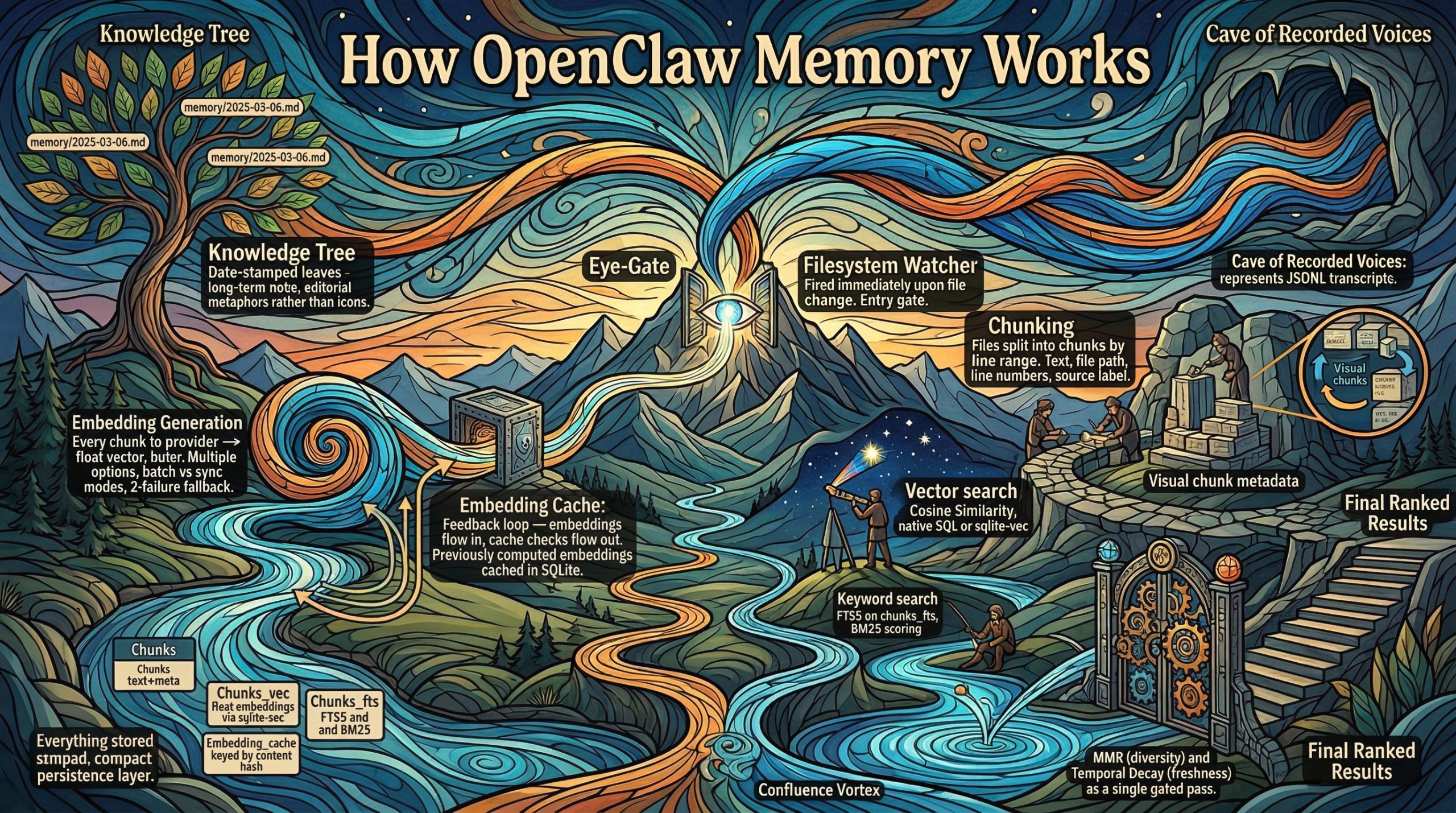
Car voilà, le grand mot est lâché : l'agentique, comme n'aurait pas su dire l'autre - ni les autres d'ailleurs -, c'est maintenant. Comme rapporté dans une lointaine Chronique de l'IA, Microsoft nous la promettait pour 2024, si bien qu'il aura donc fallu attendre un peu, mais pas trop tout de même. Le temps que les LLMs soient perfectionnés en ne cherchant plus uniquement à les faire plus grosses que le boeuf, notamment en leur apprenant à utiliser des outils puis à "raisonner", et qu'ils soient logés au sein d'outils qui les font tourner comme si c'étaient des CPUs, je veux parler du fameux Clawdbot, Moltbot, enfin bref - je vais y arriver - OpenClaw.
Le homard aux pinces rouges à pour le moins semé la zizanie. Dans la foulée de son succès fulgurant, il a donc été adopté par OpenAI, dont les concurrents ont brutalement sorti leur agent du bac à sable où il batifolait jusqu'alors gentiment, ou en ont conçu un qui fait comme les grands quand ils n'avaient pas encore de rejeton de cet acabit. Comme toujours, le cas de Microsoft est assez exemplaire. Alors que début janvier les commentateurs se gaussaient de sa déconfiture en relayant à l'envi une étude rapportant que personne n'utilisait Copilot ou presque, l'éditeur de Redmond n'a guère attendu pour se saisir de cette planche de salut en annonçant Copilot Tasks. Un énième retour du trombone diront les mauvaises langues, mais pas dit. Après tout, l'on n'est jamais à l'abri d'un succès dans cette nouvelle économie où chacun finit par se faire à l'idée qu'il y a moins bien, mais c'est plus cher, surtout quand décideur dans une entreprise / administration / chimère, il ne connaît - par définition ? - rien à l'IA.
Enfin bref, plus que jamais "le trouble et l'agitation sont considérables", comme l'a écrit Michel Houellebecq dans un de ses romans très déprimants, mais bien écrits1. Sa subjugation par l'IA ne pouvant plus être ignoré, ne nous résignons donc pas, comme le héros du récit, à ne plus être de ce monde sans pour autant trouver le courage de le quitter, mais élançons-nous y, et joyeusement. Après tout, dans la foulée de ma première interaction avec ChatGPT, n'avais-je pas écrit dans un article, que "tous ceux qui diront ne pas l'utiliser seront soit des menteurs, soit des idiots" ? Désormais que par le truchement d'un agent, le LLM n'est plus loin d'être logé au coeur du système d'exploitation comme dans la vision d'Andrej Karpathy, il est temps de savoir de quel côté de la barrière l'on entend finalement se placer.
Les infographistes n'ont plus la banane
Qui suit l'actualité de l'IA générative au quotidien n'a pu manquer de relever combien elle est cadencée par la sortie de modèles. Le public étant aux aguets de la moindre nouveauté, il ne s'écoule guère quelques heures avant qu'il ne se prononce sur le nouveau-venu. Il peut alors y avoir des flops, comme GPT-5 aux performances jugées décevantes, Sam Altman reconnaissant de plus que pour le lancer, OpenAI avait totalement merdé. Toutefois, c'est assez l'exception. Il y a beaucoup de tops, et la question est surtout de savoir combien de temps un nouveau modèle va parvenir à occuper le devant de la scène.
A ce petit jeu, dans le domaine de la génération d'images, Google a remarquablement sorti son épingle du jeu. Depuis sa sortie en août dernier, Nano Banana, ou plus exactement Gemini 2.5 Flash, a occupé le devant de la scène. Un succès mérité au regard des performances d'un modèle très innovant. En effet, comme l'a expliqué Olivier Wang, tech lead sur le modèle chez Google DeepMind, lors d'un entretien accordé à The TWIML AI Podcast :
So the thing that we're really proud of in the Gemini 2.5 Flash Image model is that we've integrated it into Gemini which means we can take advantage of all the world knowledge I was talking about earlier.
So for Imagen you know you can generate very good images but you have to be very explicit about what you want to generate. And with Nano Banana, it's possible to have prompts that are much more seeking input or information from the AI model itself. So we see people asking kind of like high abstract prompts and the model is able to do a much better job of of deciding what it is the user is trying to ask and then coming up with a reasonable response and image to satisfy this request.
So for Imagen you know you can generate very good images but you have to be very explicit about what you want to generate. And with Nano Banana, it's possible to have prompts that are much more seeking input or information from the AI model itself. So we see people asking kind of like high abstract prompts and the model is able to do a much better job of of deciding what it is the user is trying to ask and then coming up with a reasonable response and image to satisfy this request.
Bref, le générateur d'images, c'est toujours Jackson Pollock, sauf qu'on lui aurait greffé un cerveau. Forcément, ça ne s'utilise plus de la même manière, et ça ne produit pas les mêmes résultats.
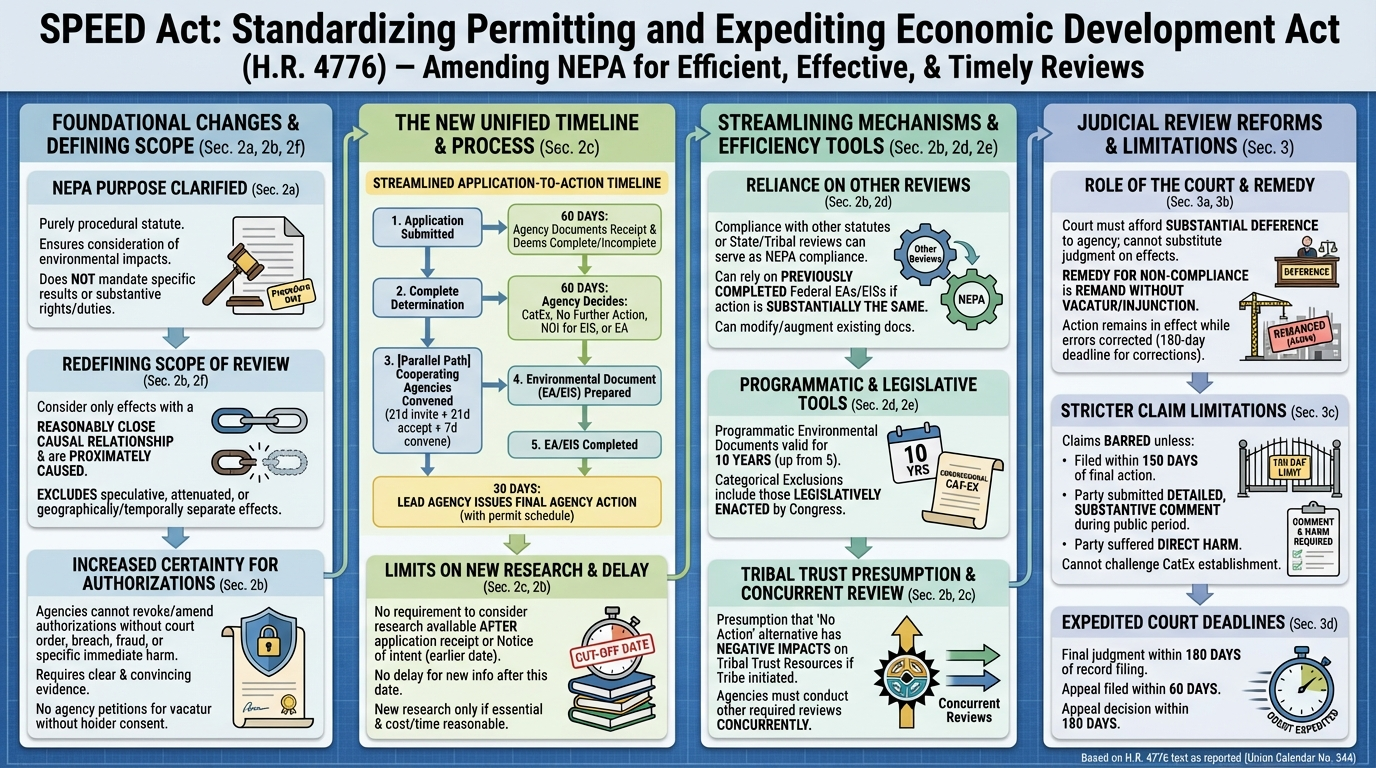
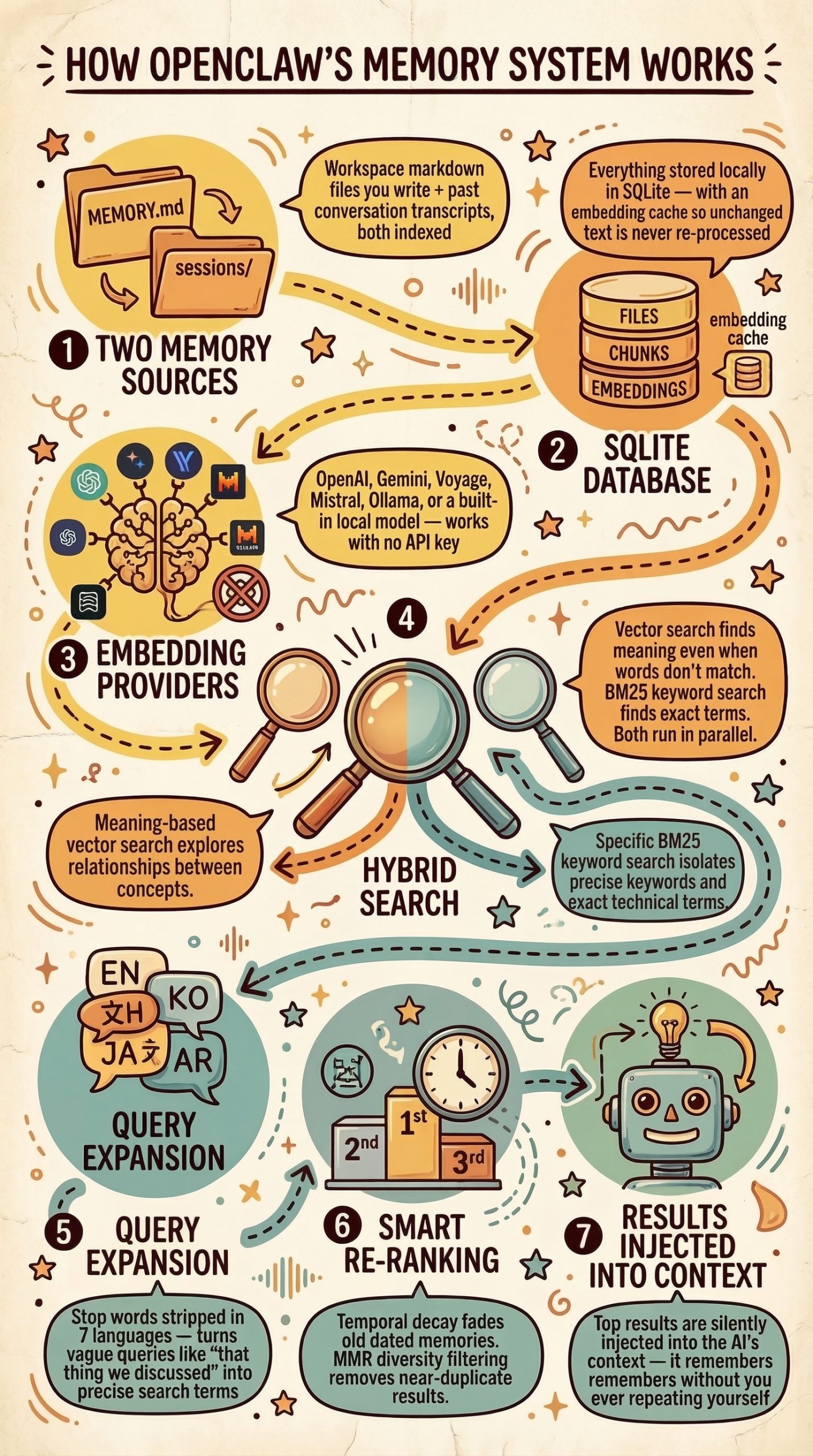
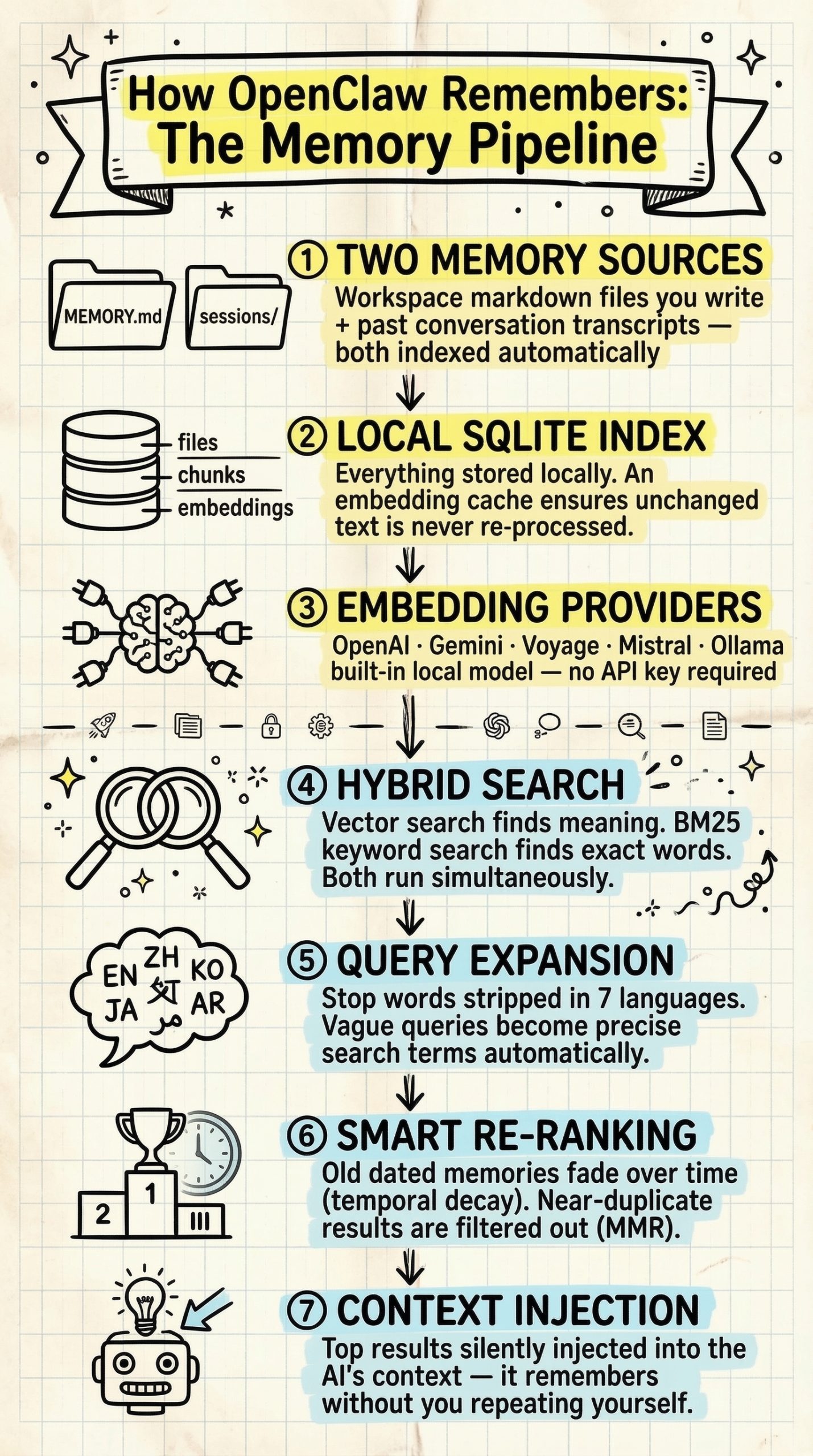
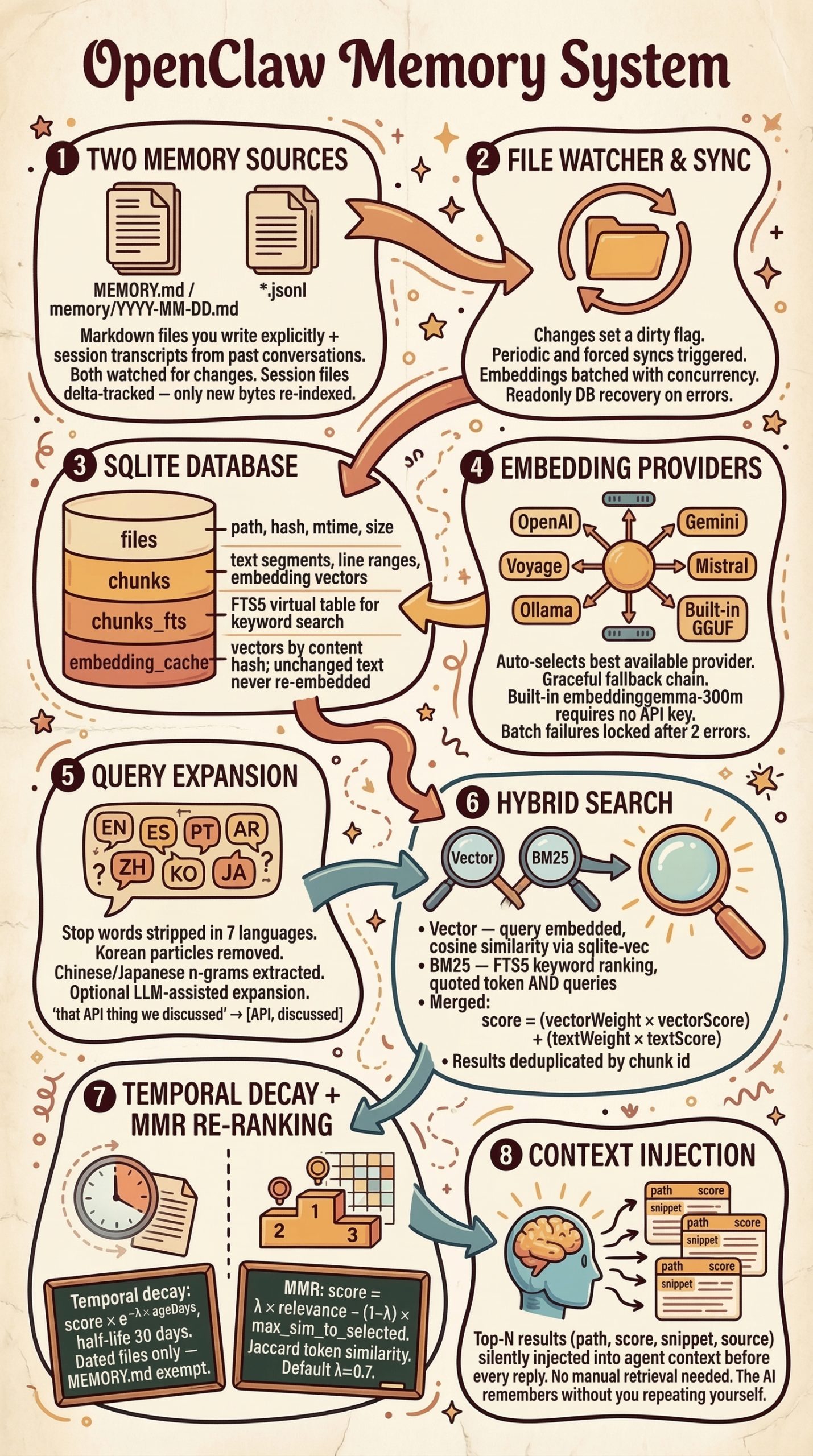
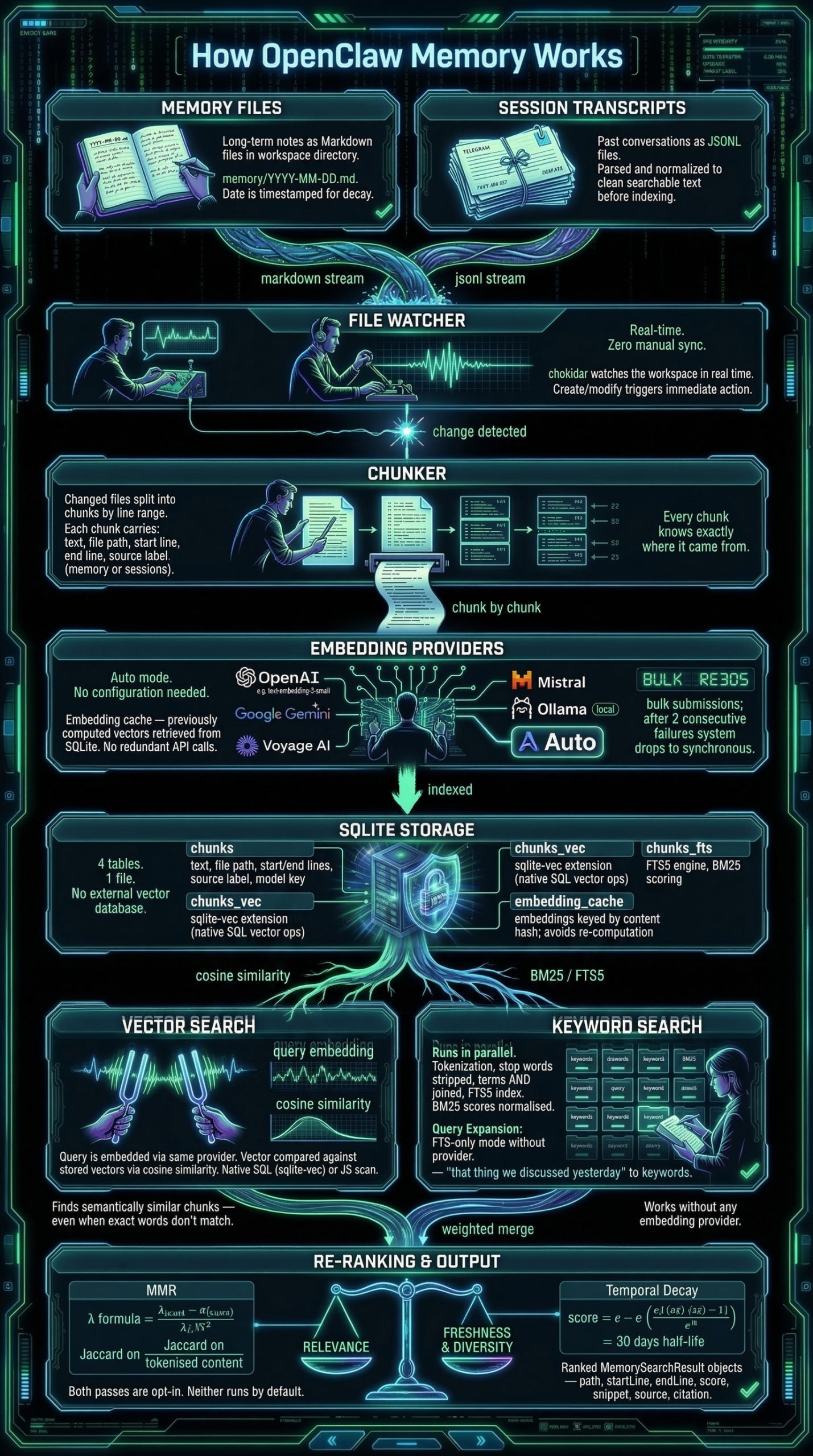
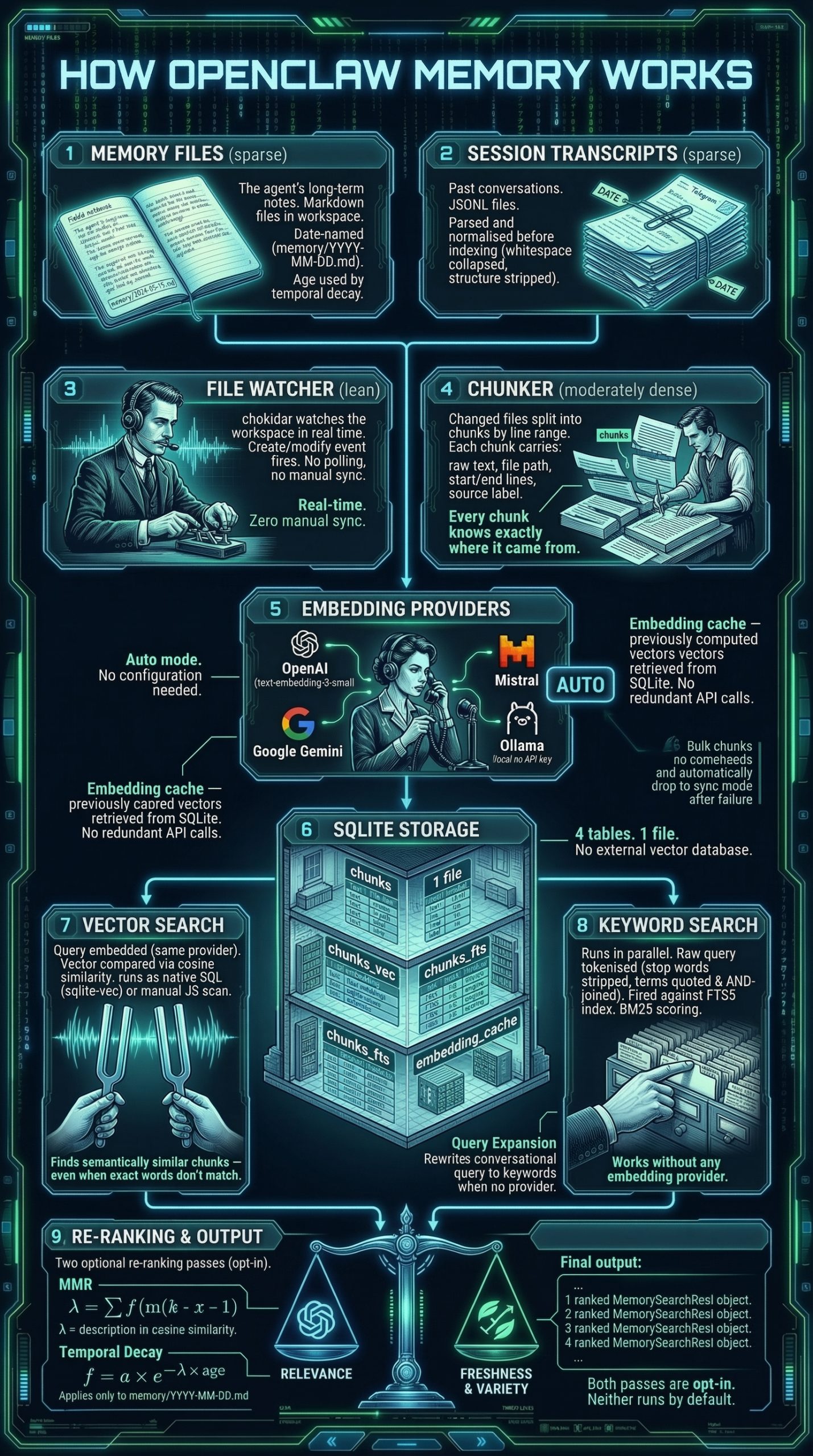
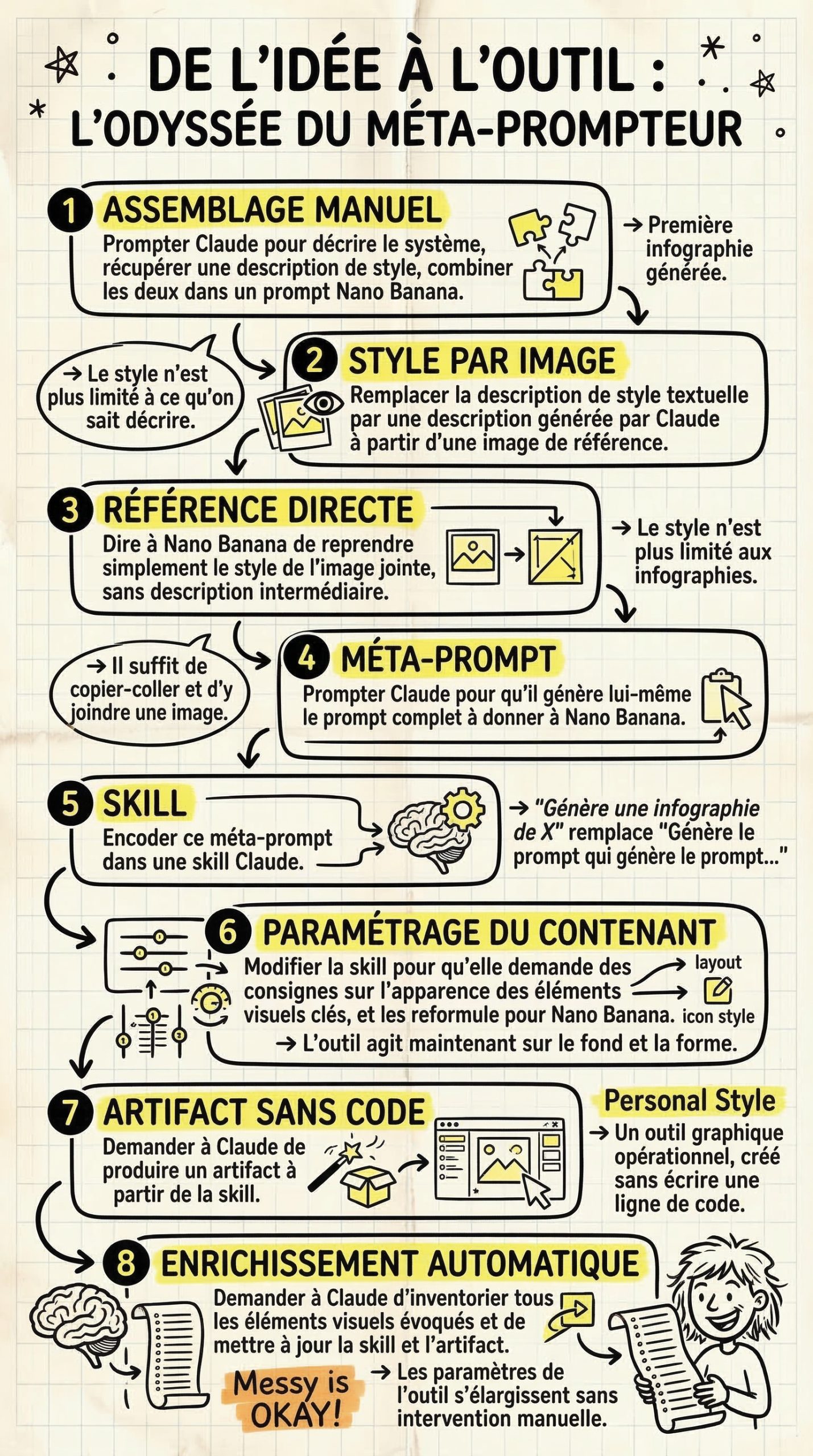
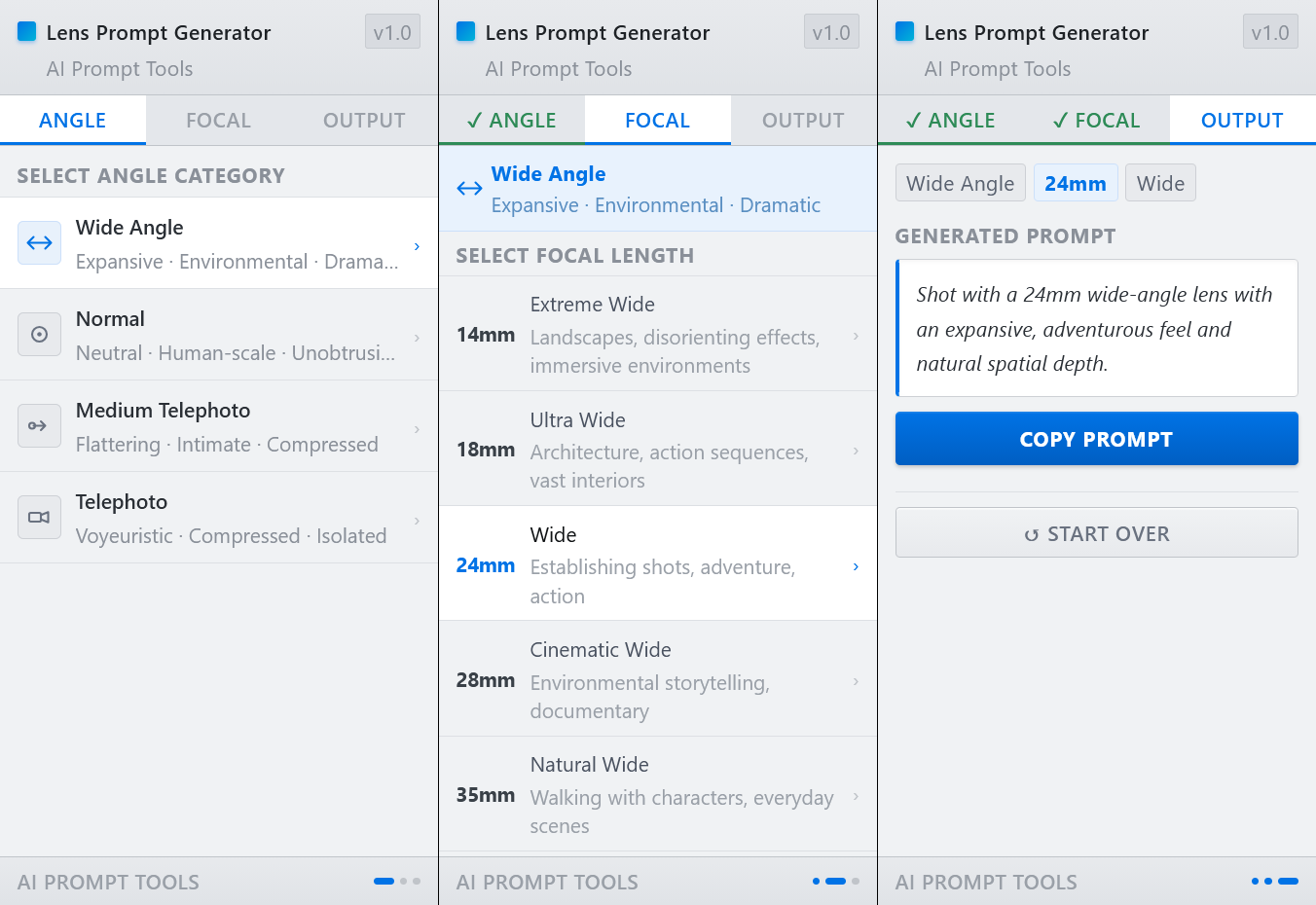
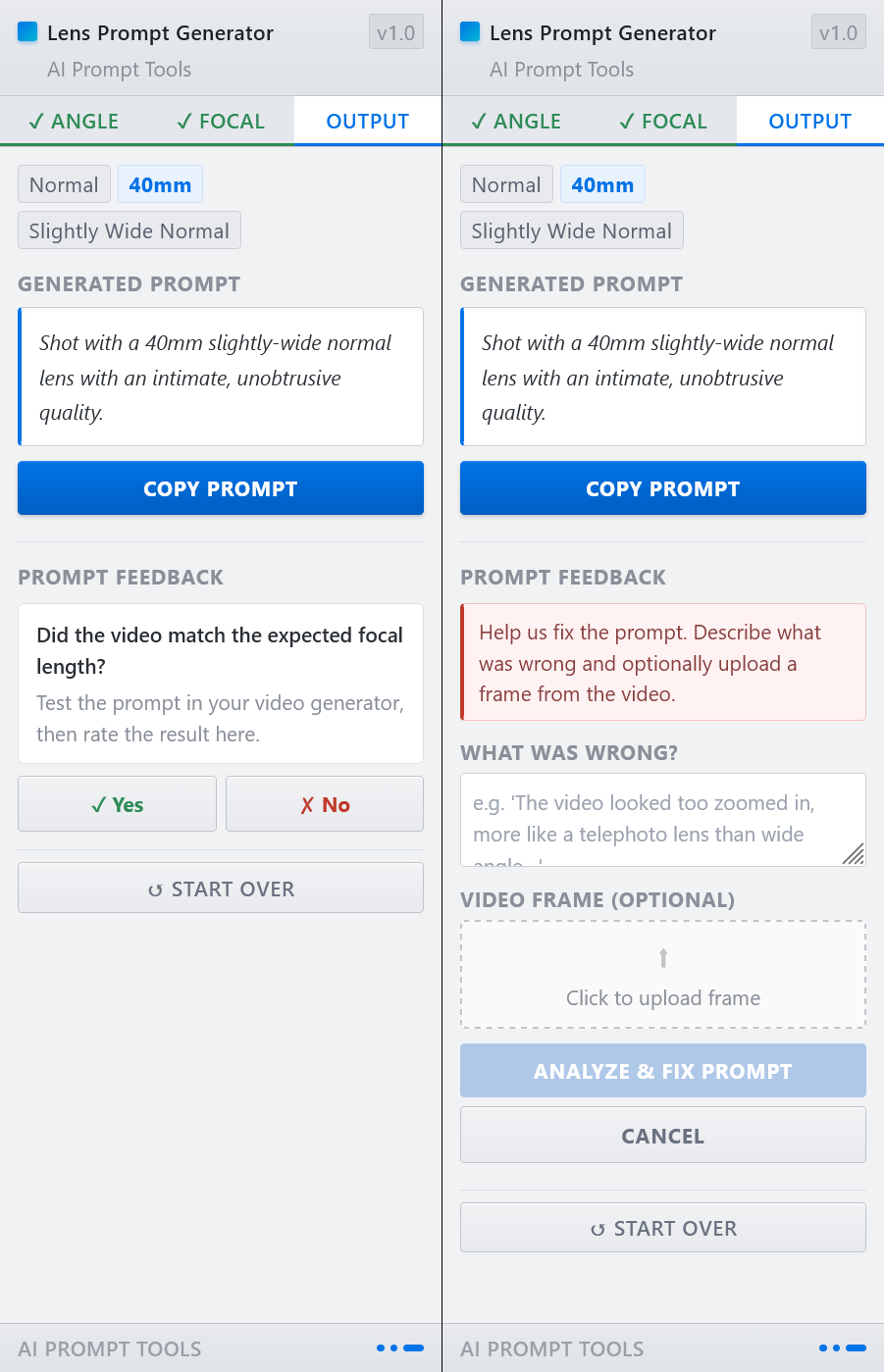
En particulier, Nano Banana s'est distingué par sa capacité à générer des infographies. L'on en trouve des exemples aussi foisonnants que fascinants sur le site du GDELT Project, qui est allé jusqu'à lui faire avaler les milliers de pages des réglementations les plus absconses pour voir ce qu'il pouvait en sortir.