Du point de vue d'un développeur, il semble que nombre des nouvelles technologies qui fleurissent avec l'IA générative ressemblent à d'autres passées.
Cela conduit à se poser quelques questions :
- Sommes-nous en train de réinventer la roue ?
- Que reste-t-il à réinventer ?
- Qu'est-ce qu'il sera impossible de réinventer ?
- Pourquoi tout ce qu'il est possible de réinventer n'a pas encore été réinventé ?
- L'IA générative peut-elle aider à accélérer le mouvement ?

Sous réserve de contrôle des hallucinations - mais on voulait qu'il soit créatif -, une intéressante conversation (en anglais) avec Claude sur le sujet...
This conversation occurred as I was trying to learn more about how to spare tokens, and it quickly led me to the subject.
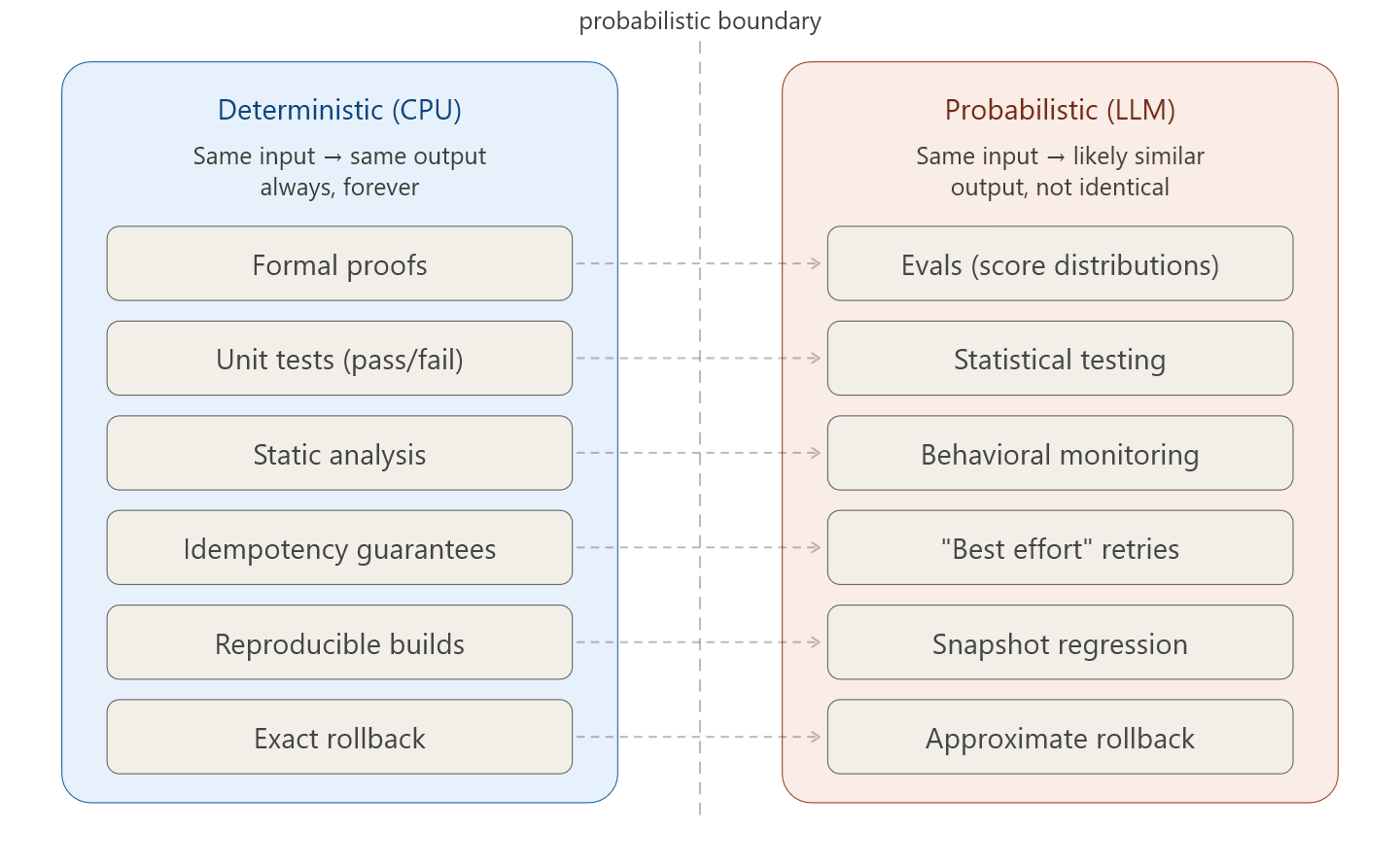
Optimizing the consumption of tokens looks very similar to the ways we optimize memory usage in a computer, the usage of a network connection, and so on. Is there something really new in the way we build systems based on an LLM compared to the way we build systems based on traditional computers?
That's a profound observation - and honestly, the answer is mostly no, but with a few genuinely new things.
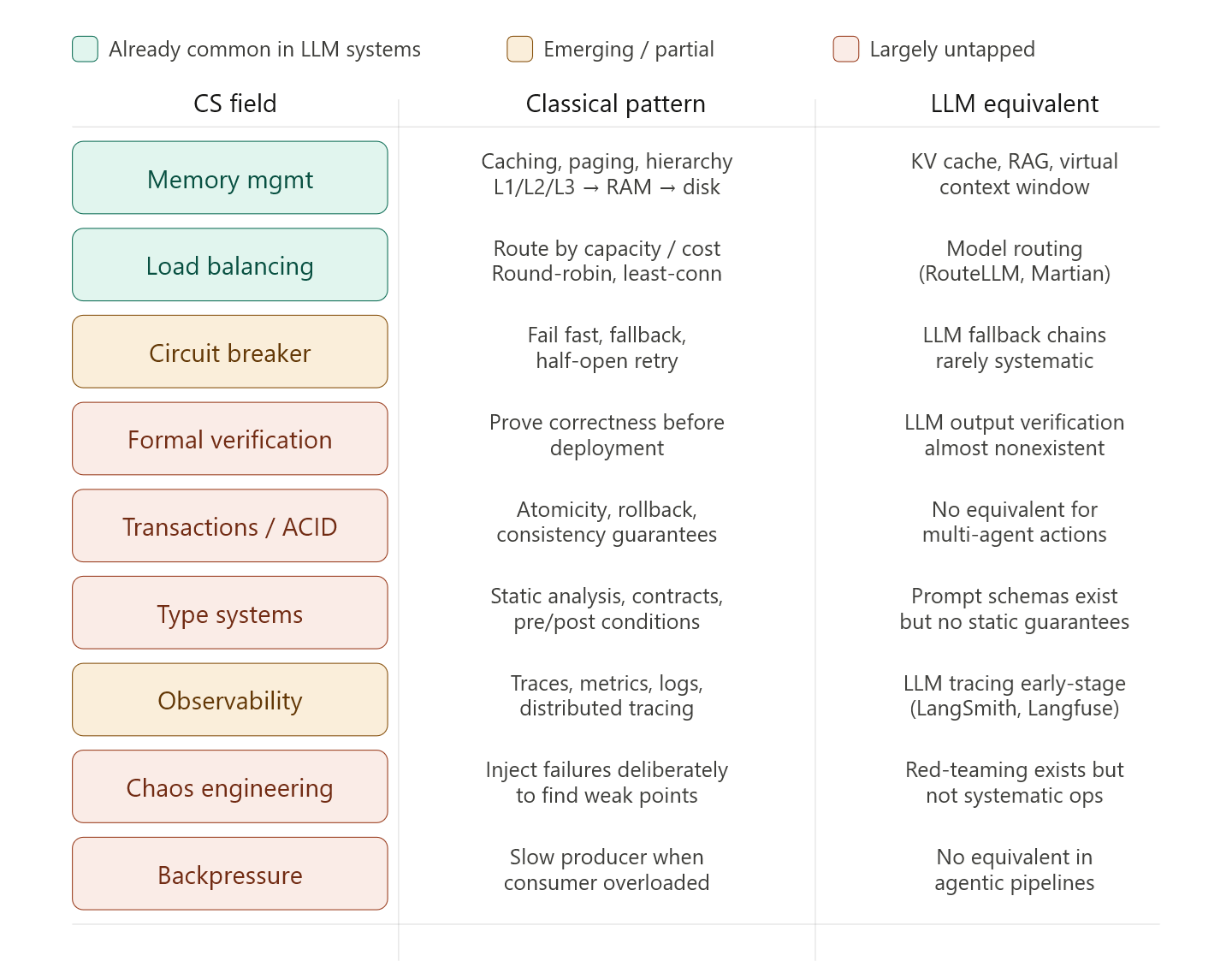
What's clearly recycled
The parallels are striking and deliberate:
- Virtual context window → virtual memory & paging
- Semantic caching → CPU cache hierarchies (L1/L2/L3)
- RAG → demand paging / lazy loading
- Token routing to cheaper models → CPU frequency scaling, QoS traffic shaping
- Prompt compression → data compression, network packet optimization
- Conversation summarization → lossy compression, delta encoding
- Agent tool calls → syscalls, interrupt handlers
- Memory tiers (working / episodic / semantic) → registers → RAM → disk hierarchy
Systems engineers from the 1970s would recognize almost all of these patterns immediately. We're largely rediscovering the same solutions because we're facing the same fundamental constraints: scarce expensive fast memory vs. abundant cheap slow memory, finite bandwidth, latency tradeoffs.
What is genuinely new
There are a handful of things that don't have clean analogies in classical systems:
1. The resource itself is a reasoning engine, not a processor
A CPU executes instructions deterministically. An LLM interprets inputs and produces outputs probabilistically. This means:
- The "quality" of a computation is fuzzy and context-dependent
- You can trade correctness for cost in ways classical systems can't
- The system can be wrong in semantic ways that have no equivalent in CPU architecture